شبکه عصبی درهم پیچیده یا کانولوشن (Convolutional Neural Network) یا به اختصار (CNN) یک نوع خاص از شبکه عصبی عمیق یا همان یادگیری عمیق (Deep Neural Network) می باشد که در مشکلات بینایی کامپیوتری (Computer Vision) عملکرد چشم گیری دارد . به طور مثال در طبقه بندی تصاویر ، تشخیص اشیاء و … استفاده میشود.
در این مقاله ما قصد داریم که یک دسته بندی کننده تصاویر (Image Classification) با کمک تنسورفلو بسازیم و این کار را با استفاده از پیاده سازی CNN انجام میدهیم تا تصاویر سگ ها و گربه ها را دسته بندی کنیم.
در برنامه نویسی سنتی این ممکن نیست که یک راه حل مقیاس پذیر برای مسائلی مانند بینایی کامپیوتر ساخت که با یک الگوریتم برای شناسایی ماهیت موجود در تصاویر به اندازه کافی خوب باشد.
با کمک یادگیری ماشین ما میتوانیم به وسیله آموزش دادن مدلی برای مثالهای داده شده ، به پیشبینی تقریبی دادههای دیده نشده بپردازیم که برای استفاده موضوعی کافی باشد.
شبکه عصبی درهم پیچیده یا کانولوشن (CNN) چطور کار میکند:
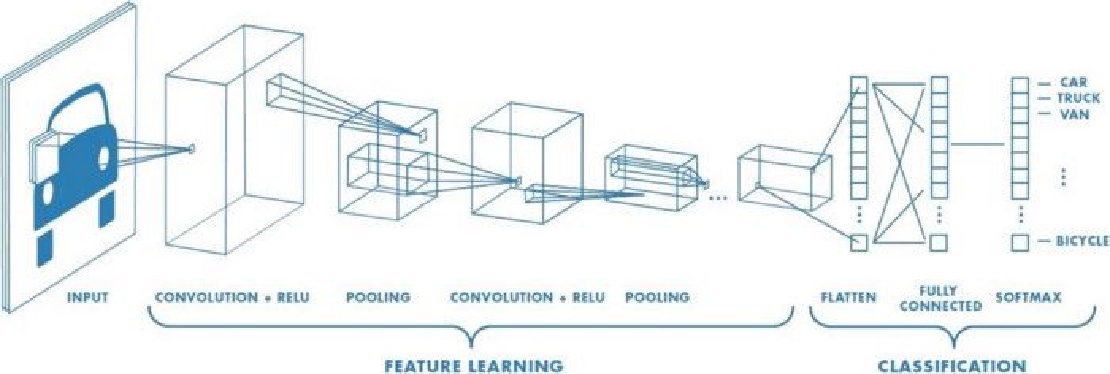
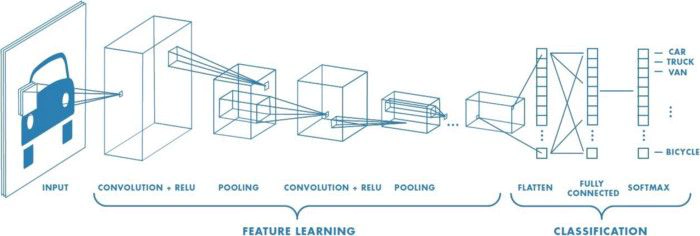
این شبکه عصبی (CNN) از چندین لایه ی پیچشی (convolution layers) و لایه های ادغام کننده (pooling layers) و لایه های متراکم (dense layers) ساخته شده است.
ایده اصلی این لایه های پیچشی یا کانولوشن (convolution layers) این است که تصاویر ورودی را طوری تغییر دهد و تبدیلاتی انجام دهد که بتوان از این تغییرات مشخصه هایی (نظیر گوش و بینی و پاها) از سگ ها و گربه ها را استخراج کند و انها را به صورت متمایز برای هر گونه (سگ یا گربه) درست انتخاب کند.
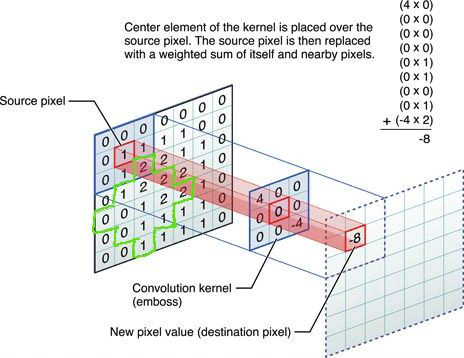
این کار با درگیر کردن داده های تصاویر با یک کرنل (kernel یا هسته) انجام میشود.
یک کرنل فیلتر خاصی است که جهت استخراج ویژگی های مشخصی از تصاویر استفاده میشود.
همچنین استفاده از چندیدن فیلتر کرنل (چندیدن کرنل) جهت استخراج چندین مشخصه از یک تصویر نیز امکان پذیر است .
معمولا یک تابع فعال سازی (activation function) به طور مثال با اسم های (tanh یا relu) به مقادیر پیچیده شده ی حاصل از ترکیب کرنل و داده های تصویر اعمال میشود تا غیر خطی بودن را بتوان افزایش داد.
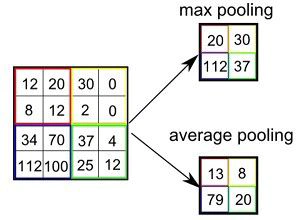
کار اصلی لایه های ادغام کننده (pooling layers) این است که اندازه و ابعاد تصویر را کاهش دهد.به واسطه این کار فقط مشخصه های مهم از تصویر باقی می ماند و باقی قسمت ها و نواحی تصویر حذف میگردد.استفاده از این لایه ها هزینه پردازشی را نیز کاهش میدهد و باعث بهبود سرعت محاسبه می گردد.
یکی از مهم ترین استراتژی و روش های ادغام ، تجمع حداکثری (max-pooling) و همچنین جمع آوری متوسط (average-pooling) میباشد.
در حقیقت اندازه ماتریس ادغام (فیلتر ادغام) ، میزان کاهش تصویر را مشخص میکند.
به طور مثال یک ماتریس 2x2 اندازه تصویر را 50% درصد کاهش خواهد داد.
این مجموعه از لایه های پیچشی یا کانولوشن (convolution layers) و لایه های ادغام کننده (pooling layers) به ما کمک خواهد کرد تا مشخصه های مهم در تصویر را پیدا کنیم و بعدا از لایه های متراکم (dense layers) برای یادگیری و پیشبینی استفاده خواهد شد.
ساخت یک طبقه بندی کننده تصویر:
شبکه عصبی درهم پیچیده یا کانولوشن (CNN) یک نوع از شبکه عصبی عمیق (Deep Neural Network) می باشد که جهت آموزش و یادگیری ماشین نیاز به قدرت محاسباتی و پردازشی زیادی دارد.علاوه بر این جهت بدست آوردن دقت کافی در ساخت مدل (Model) باید دیتاست یا مجموعه داده ما نسبتا بزرگ باشد.
از این رو کدهای برنامه نویسی را در Google Colab اجرا میکنیم که یک پلتفرم با هدف توسعه و تحقیقاتی می باشد.این Colab از سخت افزار GPU نیز پشتیبانی میکند که سرعت فرایند یادگیری و آموزش (training) را تقویت می کند.
دانلود و بارگذاری دیتاست:
این دیتاست شامل 2000 تصاویری از سگ ها و گربه ها میباشد که فرمت آن JPG است.اول نیاز داریم که این دیتاست را دانلود و فایل ZIP آن را استخراج (extract) کنیم.(در اینجا دیتاست در پوشه tmp/ بارگذاری میشود )
دانلود دیتاستاستخراج و بازکردن فایل ZIP دیتاست
پوشه باز شده شامل 2 زیرپوشه با نام های train و validation می باشد.این دو پوشه جهت آموزش داده و تست کردن ، مورد استفاده قرار خواهند گرفت.داخل هر دو پوشه همچنین 2 زیر پوشه دیگر نیز وجود دارد که شامل عکس های مجزا از سگ ها و گربه ها میشود و ما به راحتی میتوانیم از این پوشه ها جهت تست و آموزش در داخل تنسورفلو استفاده کنیم.در حقیقت ما دو نوع کلاس داده داریم (سگ ها و گربه ها) که به وسیله ی مولدهای داده (Data Generator) در تنسورفلو مورد استفاده قرار میگیرد.
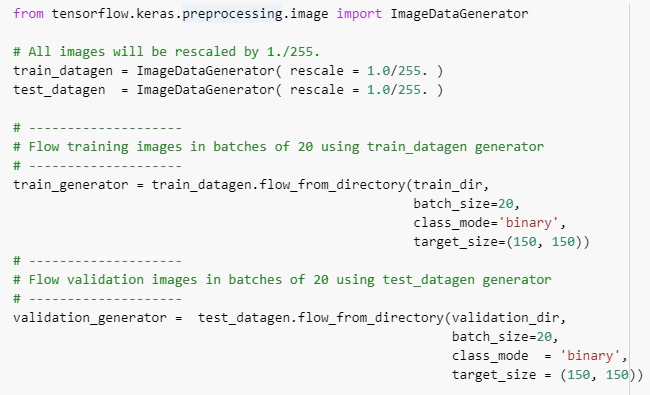
مشخص کردن مسیر تصاویر تست و آموزش در برنامهبارگذاری داده ها توسط مولد داده تصاویر در تسورفلو
در اینجا ما دوتا مولد داده (Data Generator) برای تست و آموزش داریم.هنگام بارگذاری داده ها، مقیاس مجدد (1/255) برای نرمال سازی (normalize) مقادیر پیکسل جهت همگرایی سریعتر مدل اعمال می شود.
علاوه بر این هنگام بارگذاری داده ها ما از دسته های 20 تایی تصاویر استفاده میکنیم و همه آنها به اندازه 150X150 تغییر اندازه داده شده اند.اگر تصاویری اندازه متفاوتی داشته باشند این کار باعث یکسان سازی اندازه ها میشود.
ساخت مدل:
قبلا داده ها در برنامه بارگذاری و آماده شده است اکنون ما میتوانیم مدل را بسازیم.در اینجا من از 3 لایه کانولوشن یا پیچشی (convolutional layers) و سپس 3 لایه تجمع حداکثری (max-pooling) استفاده خواهم نمود.سپس یک لایه Flatten و در نهایت از 2 لایه متراکم (Dense layers) استفاده خواهم نمود.
ساخت مدل CNN
در سه لایه کانولوشن اول من از 16 کرنل استفاده کردم که اندازه هر کرنل یک ماتریس 3x3 می باشد.زمانی که فیلتر های کرنل با تصویر درهم امیخته شد به تابع فعال سازی (activation function) با نام relu فرستاده میشود تا مقداری غیر خطی بدست آید.شکل ورودی به این لایه باید 150x150 باشد که قبلا این تغییر اندازه را اعمال کرده ایم.همچنین تمام تصاویر رنگی هستند و شامل سه کانال رنگی RGB (قرمز-سبز-آبی) می باشند.
در لایه max-pooling من یک کرنل 2x2 اضافه کردم که بزرگترین مقادیر را انتخاب خواهد کرد و باعث خواهد شد تصویر ما 50% درصد کاهش اندازه پیدا کند.
این دو دسته ی (convolution و max-pooling) سه لایه ای ها جهت استخراج مشخصه هایی از تصویر بکار گرفته شده اند.اگر پیچیدگی و سختی مشخصه ها زیادتر از انتظار باشد ، باید لایه های بیشتری اضافه کنیم تا مدل عمیق تری بسازیم.
لایه Flatten خروجی را از آخرین لایه max-pooling میگیرد و آن را تبدیل به یک آرایه یک بُعدی میکند.این لایه یک بُعدی میتواند خوراک لایه های Dense ما بشود.
لایه متراکم Dense یک لایه منظم از نورون ها در یک شبکه عصبی می باشد.اینجاست که فرایند حقیقی یادگیری اتفاق می افتد و وزن ها (weights) تنظیم میگردند.
در اینجا ما 2 لایه متراکم Dense داریم و از آنجایی که این یک طبقه بندی باینری (دودویی) است، تنها 1 نورون در لایه خروجی وجود دارد.
تعداد نورون ها در لایه دیگر را می توان به عنوان یک فراپارامتر تنظیم کرد تا بهترین دقت را به دست آورد.
آموزش (Train) مدل:
قبلا ما یک مدل را ساختیم و اکنون میتوانیم آن را کامپایل و گردآوری کنیم.
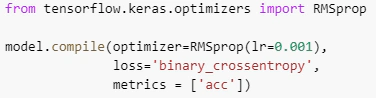
کامپایل مدل
در اینجا باید نحوه محاسبه ضرر (loss) یا خطا (error) را تعریف کنیم.
از آنجایی که ما از یک طبقه بندی باینری استفاده می کنیم، می توانیم از binary_crossentropy استفاده کنیم.
با پارامتر بهینه کننده، نحوه تنظیم وزن ها در شبکه را به گونه ای ارسال می کنیم که ضرر یا loss کاهش یابد.
گزینه های زیادی وجود دارد که می توان از آنها استفاده کرد و در اینجا من از روش RMSprop استفاده می کنم.
در نهایت، از پارامتر متریک (قابل سنجش) برای تخمین اینکه مدل ما چقدر خوب است استفاده می شود و در اینجا از دقت یا accuracy استفاده می کنیم.
حالا ما میتوانیم آموزش دادن مدل را شروع کنیم.
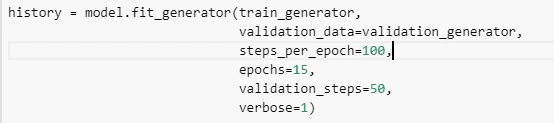
آموزش دادن مدل
در اینجا ما داده هایی که برای train و validation توسط مولد بارگذاری کرده بودیم را به عنوان ورودی میدهیم.
آنجایی که مولد داده ما دارای اندازه ی 20 دسته ای برای ورودی است، باید 100 step_per_epoch (گام در هر دوره) داشته باشیم تا همه 2000 تصویر آموزشی و 50 مورد برای تصاویر اعتبارسنجی را پوشش دهیم.
پارامتر epochs تعداد تکرارهایی را که برای آموزش انجام می دهیم را تعیین می کند.
باقی پارامتر ها پیشرفت در هر تکرار را در حین آموزش نشان می دهد.
نتیجه 15 گام (epochs)
پس از 15 دوره، مدل 98.9% دقت را در مجموعه آموزشی و 71.5% دقت را در مجموعه اعتبار سنجی کسب کرده است.
این نشانه واضحی است که مدل ما بیش از حد برازش (overfit) شده است و این یعنی مدل ما در داده های مجموعه آموزشی (train data) بسیار خوب عمل خواهد کرد و برای داده های دیده نشده عملکرد ضعیفی خواهد داشت.
برای حل مشکل اضافه برازش (overfitting)، هم میتوانیم منظمسازی (regularization) اضافه کنیم تا از پیچیدهشدن بیش از حد (over-complexing) مدل جلوگیری کنیم، هم میتوانیم دادههای بیشتری را به مجموعه آموزشی اضافه کنیم تا مدل برای دادههای دیده نشده بهینه تر شود.
از آنجایی که ما یک مجموعه داده بسیار کوچک (2000 تصویر) برای آموزش داریم، اضافه کردن داده های بیشتر باید مشکل را برطرف کند.
جمعآوری دادههای بیشتر برای آموزش یک مدل در یادگیری ماشین بسیار دشوار است، زیرا برای این کار پیشپردازش مجدد دادهها لازم است.اما هنگام کار با تصاویر، به خصوص در طبقه بندی تصاویر، نیازی به جمع آوری اطلاعات بیشتر نیست. این مشکل را می توان با تکنیکی به نام تقویت تصویر (Image Augmentation) برطرف نمود.
تقویت تصویر (Image Augmentation):
ایده تقویت تصویر ایجاد تصاویر بیشتر با تغییر اندازه، بزرگنمایی، چرخش تصاویر و غیره برای ساخت تصاویر جدید است.با این رویکرد، مدل میتواند ویژگیهای بیشتری را نسبت به قبل ثبت کند و به خوبی برای دادههای دیده نشده بهینه شود.
به عنوان مثال، بیایید اکثر گربه های موجود در مجموعه آموزشی خود را به صورت زیر فرض کنیم که بدن کامل یک گربه را دارند. مدل سعی خواهد کرد شکل بدن گربه را از این تصاویر یاد بگیرد.
به همین دلیل، طبقهبندیکننده ممکن است نتواند تصاویری مانند تصویر زیر را به درستی شناسایی کند، زیرا با نمونههای مشابه آن آموزش ندیده است.
اما با تقویت تصویر، میتوانیم تصاویر جدیدی از تصاویر موجود بسازیم تا طبقهبندی کننده ویژگیهای جدیدی را یاد بگیرد.با قابلیت بزرگنمایی در تقویت تصویر، میتوانیم یک تصویر جدید مانند زیر بسازیم تا به یادگیرنده کمک کنیم تصاویری مانند بالا را که قبلاً به درستی طبقهبندی نشدهاند طبقهبندی کند.
تصویر زوم شده از تصویر اصلی با تقویت تصویر
افزودن تصویر تقویتی با مولد تصویر (image generator) در تنسورفلو بسیار آسان است.هنگامی که تقویت تصویر اعمال می شود، مجموعه داده اصلی دست نخورده باقی می ماند و تمام دستکاری ها در حافظه انجام می شود.
تکه کد زیر نحوه افزودن این قابلیت را نشان می دهد.
افزودن تقویت تصویر هنگام بارگیری داده ها
در اینجا چرخش تصویر، جابجایی، بزرگنمایی و چند تکنیک دستکاری تصویر دیگر برای تولید نمونه های جدید در مجموعه آموزشی اعمال می شود.
هنگامی که ما تقویت تصویر را اعمال می کنیم، می توان 86٪ دقت آموزشی و 81٪ دقت تست را به دست آورد.
همانطور که می بینید این مدل مانند قبل اضافه برازش (overfit) نشده است و با مجموعه داده بسیار کوچکی مانند این، این دقت چشمگیر است.
علاوه بر این، میتوانید دقت را با بازی با فراپارامترهایی مانند بهینهساز، تعداد لایههای متراکم، تعداد نورونها در هر لایه و غیره افزایش دهید.
ما در آغاز یک دوران انقلابی زندگی میکنیم دلیل اون توسعه ی تجزیه و تحلیل داده ها، قدرت محاسباتی بزرگ و محاسبات ابری است. یادگیری ماشین قطعا نقش مهمی در اون ایفا خواهد کرد و مغزهای پشت این یادگیری ماشین ، مبتنی بر الگوریتم هستند. این مقاله 10 تا از محبوب ترین الگوریتم های یادگیری ماشین را که در حال حاضر استفاده می شوند پوشش می دهد .











 mam_niki
mam_niki