سلام با بخش سوم رهیافت ORM با تأکید بر Hibernate در خدمت شما هستم . برای مطالعه و درک این فصل مجبور شدم علاوه بر مطالعه مطالب خود فصل ، سراغ یک روش مدل سازی نرمافزار بنام Domain Driven design بروم . درک سه مفهوم domain model , business model و data model کمی برام مشکل و گیجکننده بود . برای درک بهتر این روش مدلسازی ، کتاب Domain Driven Design نوشته Eric Evans پیشنهاد میشود خود من فرصت چندانی برای مطالعه این کتاب نداشتم بنابراین مجبور شدم با خواندن کتابچه ها و مقاله های مرتبط این سه مفهوم رو درک کنم .
در این فصل روی سه موضوع بیشتر تأکید خواهیم کرد :
- بررسی سه مفهوم domain model , business model و data model
- بررسی بهترین روشهای برنامه نویسی entity ها( کلاسهایی که اصطلاحاً بهشان POJO گفته میشود ) و استاندارد هایی که در مستندات JPA و Hibernate بهشان تأکید شده است .
- ارتباط آبجکتها در Hibernate
بررسی سه مفهوم domain model , business model و data model :
لطفاً نگاهی به نمودار زیر بیندازید !
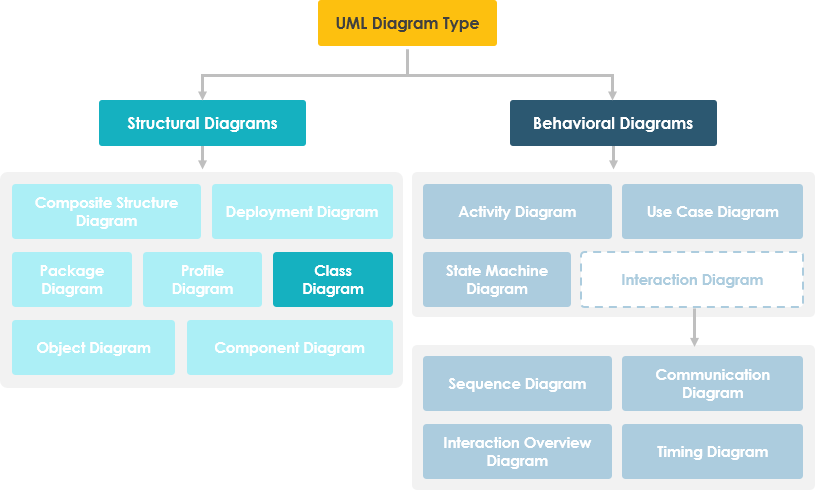
شکل بالایی مجموعهای از نمودارهای UML را نمایش میدهد که برای مدلسازی سیستم بکار میروند هریک در موقعیتها و شرایط مختلف و با اهداف و منظورهای گوناگون و مخصوص به خود .
وقتی برای اولین بار شروع به درک و مدلسازی یک سیستم میکنید اولین مستنداتی که در حین اینکار تولید میشود پایههای اولیه مدل سازی بیزنسی (business model ) را تشکیل میدهد . خیلی ساده، میخواهیم بدانیم این سیستم بایستی چه نیازهایی از مشتری را پاسخ دهد و چگونه / چه موقع این نیازها را پاسخ دهد . درک سیستم همیشه کار ساده و سرراستی نیست فرض کنید شما قصد مدلسازی سیستم شبیه سازی کنترل ترافیک خطوط هوایی آمریکا را برعهده دارید یا سیستم پرداخت یک بانک را . شما یک برنامه نویس یک طراح نرمافزار و در یک کلام شما یک متخصص حوزه IT هستید نه مهندس هواپیما نه مهندس مکانیک نه حسابدار بانک و نه ….
برای درک چنین سیستمهای پیچیدهای نیاز به دو عنوان تخصصی در تیم طراحی و تحلیل است :
- تخصص domain expert
- تخصص business analyst
متخصص domain expert : شخصی است که تخصصصش در حوزه خاصی چون کنترل هواپیما یا حسابداری بانک یا مکانیک اتومبیل و… است کسی که برای درک و مدلسازی سیستم نرم افزاری میتواند به شما ( که متخصص IT هستید ) کمک کند .
متخصص Business analyst : شخصی است که تخصصش در تحلیل و درک حوزه های تخصصی گوناگون و استخراج فرایندهای پیچیده و موجودیتهای اصلی در آن حوزه تخصصی است .
شاید تعریفی که ارایه کردم مبهم باشد!
این تعریفی است که ویکیپدیا برای business analyst ارایه کرده است :
A business analyst (BA) is someone who analyzes an organization or business domain (real or hypothetical) and documents its business or processes or systems, assessing the business model or its integration with technology.
این شخص از نظر من باید مثل یک خبرنگار خبره و سمج و بسیار کنجکاو و باهوش و خیلی با اطلاعات عمومی بالا باشد.
این دو متخصص یعنی domain expert و business analyst بایستی برای درک منظور همدیگه و ارتباط گیری باهم از یک زبان مشترک استفاده کنند . معمولاً این زبان مشترک تشکیل میشود از نمودارها و اسناد ( نوشتن نحوه کارکرد فرایندها و حتی ضمیمه کردن مستندات کاغذی موجود در محیط عملیاتی مثل فرمهای ثبت نام / فرمهای گزارش گیری و… ) و حتی دموی نرم افزاری اولیه از کار است یعنی شما یک دمو از سیستمی که مشتری میخواد بسازید و در اختیارش بگذارید و ازش بخواهید به شما فیدبک بدهد که آیا این همان سیستمی است که میخواهد یا نه !
برای درک نحوه ارتباط این دو متخصص به کتاب Eric evans مراجعه کنید مکالمه بین این دو شخص خیلی شبیه مصاحبه یک خبرنگار با یک شخصیت مریخی است !
فرض کنید شما یه موجود فضایی ( مریخی مثلاً ) گیر انداختید و ازش میخواهید براتون نحوه کارکرد یه ماشین زمان دست ساز مریخی ها را توضیح دهد حین مکالمه و پیشرفت کار انقدر فرمول ها و مفاهیم ریاضی / فیزیکی عجیب غریبی براتون میگوید که حس میکنید وسط کار مغزتون سوت میکشد و همین الانه که منفجر شود ( حالا نه انقد پیچیده ولی واقعاً کار سخت و پیچیدهای است ارتباط این دو متخصص باهم ) .
تذکر : business analyst موقع تحلیل و مدلسازی سیستم اصلاً رویکرد نرم افزاری ندارد به عبارت دیگر اون نباید چنین رویکردی داشته باشد وظیفه او فقط و فقط تحلیل و مدلسازی فرایندها و شناسایی موجودیتهای اصلی سیستم است اینکه بعداً با این مدل (business model ) قرار است چکاری بکنند برایش مهم نیست .
خروجی این مرحله business model است این مدل بعداً دست متخصص / متخصصین دیگری میرسد بنام software designer / analyst . البته بین دو متخصص business analyst و software analyst همیشه تعامل و رد و بدل کردن اطلاعات جهت درک درست تر و دقیقتر نیازمندهای سیستم وجود دارد .
همانطور که گفتیم business analyst موقع مدلسازی سیستم اصلاً با رویکرد نرم افزاری جلو نمیرود درنتیجه مدلی که ارایه میدهد ممکن است با رهیافتها و تکنولوژی ها و راه حلهای نرم افزاری همخوانی نداشته باشد برای پر کردن این شکاف از تخصص دیگری بنام طراح نرمافزار استفاده میشود این متخصصین، سیستم را از نقطه نظر نرم افزاری باز مدلسازی میکنند اصول مهندسی نرمافزار را روی آن اعمال کرده، موجودیتهای اصلی سیستم و ارتباطات بین آنها را شناسایی کرده و گاهی حتی نیاز دارند موجودیتهای فرعی دیگری به سیستم اضافه کنند جهت تطبیق با ملاحظات نرم افزاری .
خروجی این بخش domain model است .
اگر بخواهیم domain model را تعریف کنیم میتوانیم اینطوری بیانش کنیم :
مجموعهای از entity ها و رابطه بین آنها به همراه ویژگیها و رفتارهای آنها و یکسری قوانین بیزینسی حاکم برعملکرد آنها .
نکته : در رهیافت Domain driven design ما در مورد نحوه نگاشت business model به domain model سروکار داریم .
معرفی Anemic domain object :
اصطلاح anemic domain object را اولین بار مارتین فاولر برای entity هایی بکار برد که فقط حاوی وضعیت (state ) هستند و نه رفتارو آنها را جزو آنتی پترن ها معرفی کرد . طبق گفته فاولر این ایده مخالف ایده طراحی شی گرایی است چرا که در دنیای شی گرایی وضعیت به همراه رفتار در یک بسته بنام کلاس بسته بندی میشود . درواقع معصبین شی گرایی چون فاولر و اریک ایوانس معتقدند اینا object های واقعی نیستند .چرا که با هل دادن همه رفتارهای این آبجکتها به بیرون و داخل سرویس ها شما با یکسری اسکریپت ها روبرو میشویدکه فاولر به آنها اصطلاحاً transaction script ها میگوید .چنین آنتی پترن هایی در جاوا در تکنولوژی هایی چون EJB entity bean ها بسیار دیده میشود . معایبی که برای این مدل object ها بیان میکنند عبارتند از :
- چون منطق یک آبجکت در جای دیگری غیر از خودش قرار دارد بنابراین اصل encapsulation پنهان سازی اطلاعات را نقض میکند .
- باعث میشود نیاز به یک لایه سرویس داشته باشیم موقعی که domain logic را مابین مصرف کنندگان یک domain object به اشتراک بگذاریم . همچنین باعث میشود objectهای domain model نتوانند درستی خودشان را در هر لحظه از زمان تضمین کنندو نیز نوشتن unit test برای بررسی صحت عملکرد آنها مشکل است .
اما از طرف دیگر طرفداران anemic domain object ها برای آن مزایایی در نظر میگیرند که عبارتند از :
- هنگامی که با ORM و تکنولوژی های مرتبط با آن سروکار داریم عمل نگاشت سادهتر میشود ( یعنی از پیچیدگی های نگاشت کاسته میشود ) .
- مابین data و logic جداسازی رخ میدهد ( برنامه نویسی روالی ) .
جایگاه domain model entity ها در معماری سه لایهای application :
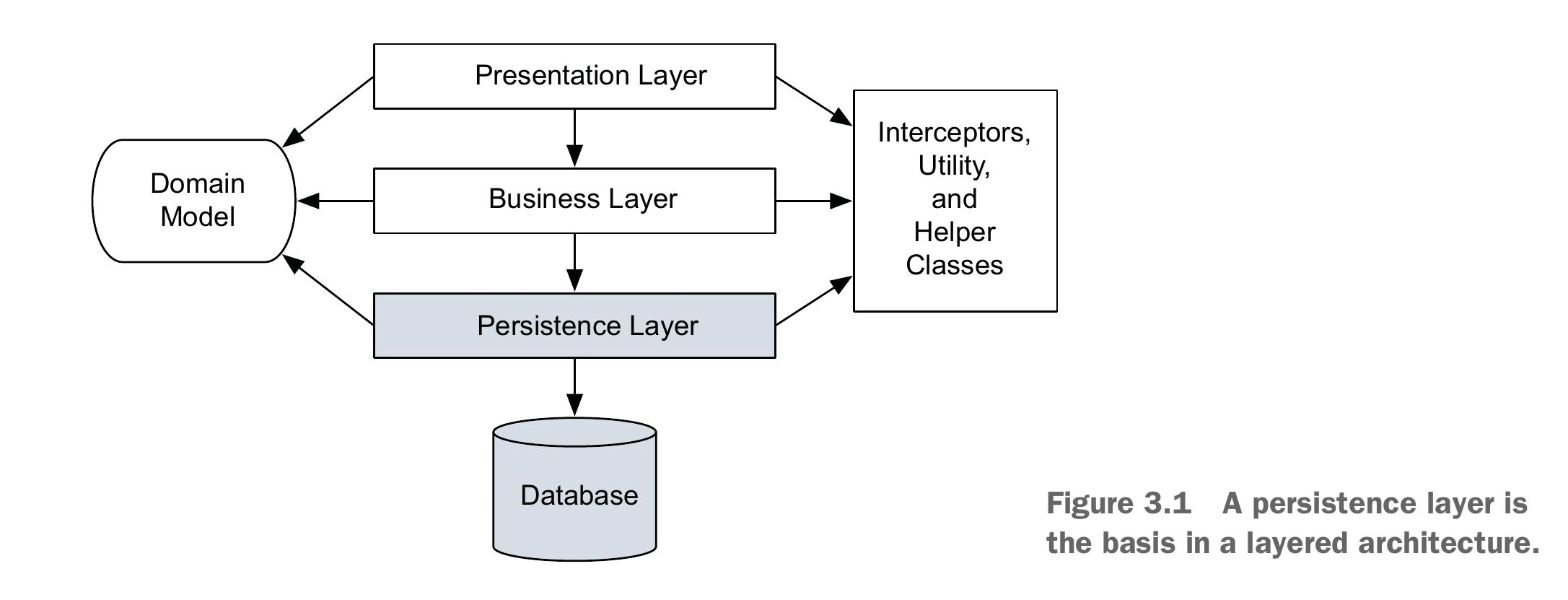
همانطور که در شکل بالایی مشاهده میکنید domain model entity ها در یک لایه خاصی ساکن نیستند بلکه توسط همه لایه ها مورد استفاده قرار میگیرند . اما نکته مهم اینجاست ، این entity ها به هیچوجه نباید حاوی هیچ concern ی جز قوانین بیزنسی حاکم برآنها باشد . به زبان ساده وقتی کد مربوط به این entity ها رو مشاهده کنید نباید درش هیچ کدی مربوط به باز کردن connection به دیتابیس مشاهده کنید یا باز کردن سوکت جهت گرفتن مقادیر و ست کردن مقدار property های متعلق به یک entity .
درواقع به هنگام پیادهسازی domain model باید به اصل separation of concern وفادار باشیم.و همیشه مطمئن باشیم غیر از جنبههای businessی ( مانند business rule ها و validation ) در entity های موجود چیز دیگری در domain model نشت نکند .
سؤال : کی از ORM در پروژه خودمان استفاده نکنیم ؟
با توجه به domain model ما میتوانیم تصمیم بگیریم از ORM استفاده کنیم یا نه . به این ترتیب که اگر app ما business rule های پیچیدهای را پیادهسازی نمیکند یا برهم کنش های پیچیده مابین entity ها وجود ندارد نیازی نیست سراغ ORM برویم و همان data model ( همون ارتباط مستقیم با دیتا بیس و جدول ها ) کارمان را راه میاندازد .
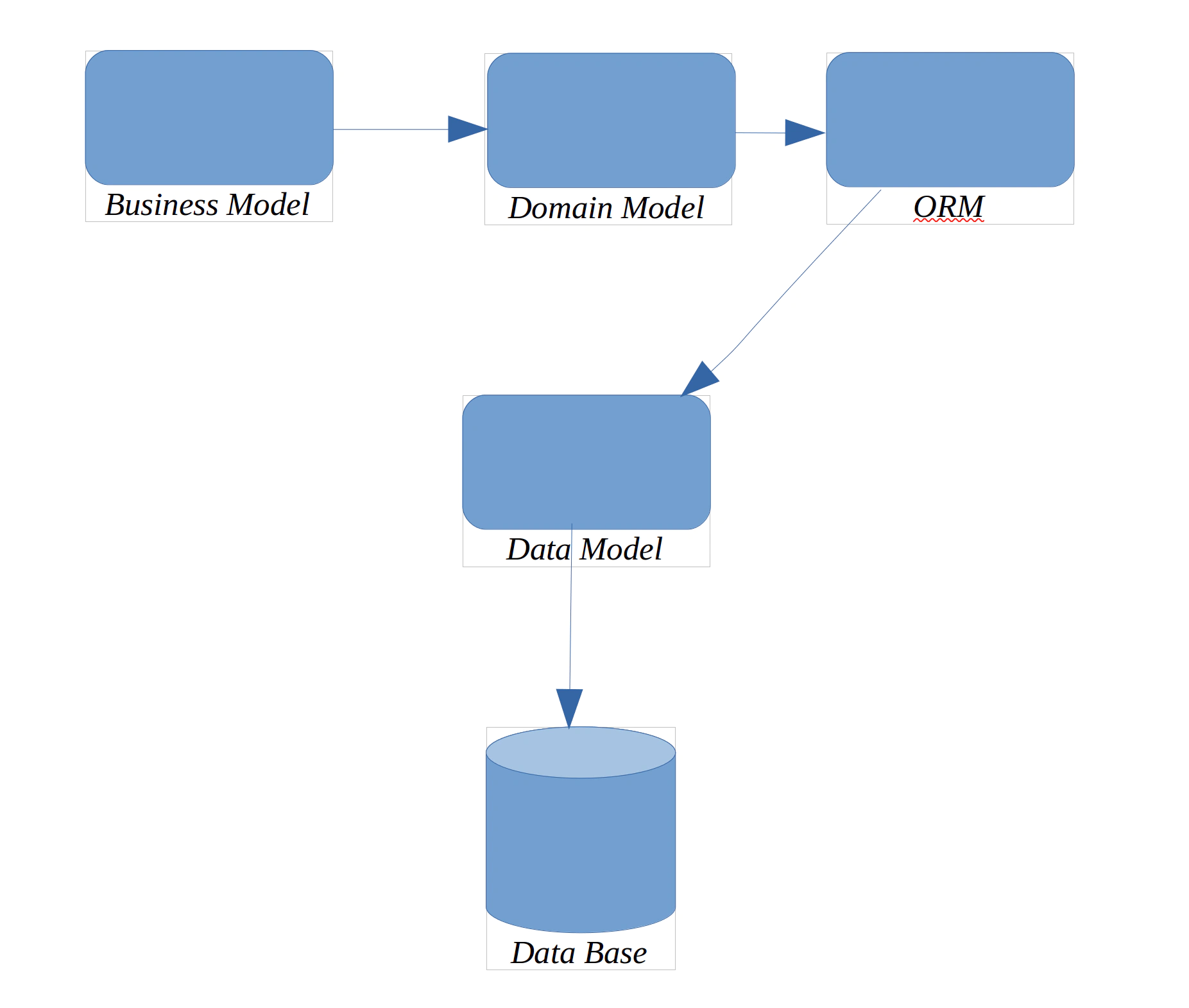
نحوه پیادهسازی Entity های domain model :
از بین entity های موجود در domain model برخی از آنها لازم است وضعیتشان در data store ذخیره شود اما رویکردی که برای ذخیره سازی در ORM و Hibernate اتخاذ میشود به گونهای است که به کمک دو مفهوم POJO object ها و meta dataها این موجودیتها را از مسایل/ مکانیسم های ذخیره سازی جدا کنیم. یعنی این آبجکتها با مسایل ذخیره سازی خود را درگیر و آلوده نکنند حتی بیخبر از مکانیسم های ذخیره سازی باشند .
معرفی POJO ها به عنوان راهکاری برای ساخت domain object ها :
POJO یا Plain Old java Object را اولین بار Martin Fowler, Rebecca Parsons و Josh Mackenzie در
سال ۲۰۰۰ ساختند و مصطلحش کردند .
این آبجکتها حاوی تعدادی attribute هستند که وضعیت (state) جاری آبجکت را نگه میدارند به همراه یک سری متدهای بیزنسی که رفتار این آبجکتها را توصیف میکنند و در نهایت یکسری ویژگیها( attribute ) که نشانگر رابطه این آبجکت با آبجکتهای دیگر است .
در زیر یک مثال از همچین آبجکتی را مشاهده میکنید :
public class User implements Serializable {
protected String username;
public User() {
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public BigDecimal calcShippingCosts(Address fromLocation) {
// Empty implementation of business method
return null;
}
// ...
}
با توجه به این نمونه مثال ویژگیها و best practice هایی که موقع دادن قابلیت ذخیره سازی به آبجکتهای domain باید رعایت کنیم در زیر به صورت خلاصه ارایه میشود :
در JPA ما نیازی نداریم آبجکتهایی که قرار است در data store ذخیره شوند واسط java.io.Serializable. را پیادهسازی کنند . اما اگر این آبجکتها بخواهند در httpsession ذخیره شوند یا بوسیله پروتکل RMI منتقل شوند پیادهسازی چنین واسطی لازم است .
خود این کلاسهایی که قابلیت ذخیره سازی در data store دارند میتوانند abstract باشند یا از یک کلاس abstract یا interface ارث بری کنند .
این کلاسها باید از نوع top level باشند به این معنی که ما نمیتوانیم یک کلاس داخلی (inner class ) را در data store ذخیره کنیم .
این کلاسها به هیچ وجه نباید از نوع final تعریف بشوندنه خود کلاس و نه هیچ کدام از متدهایش . این درواقع یک درخواست از سمت JPA__است برای کارهای داخلی خودش نیاز دارد این کلاسها و متدهایش final نباشند .
این کلاسها باید حتماً یک constructor بدون آرگومان ( default constructor ) داشته باشند_._ این یک نیاز برای JPA API ها و Hibernate API ها است چرا که اونا به کمک java reflection اقدام به ساخت نمونه آبجکتهایی از این کلاسها میکنند برای انجام کارهای داخلی خود ( مثلاً ساخت پروکسی آبجکت از آنها برای انجام عملیات بهینه سازی performance ی ) .
جالب است بدانید هایبرنت برای دسترسی به فیلدهای موجود در این کلاسها نیازی به متدهای به اصطلاح getter و setter ندارد . بلکه هایبرنت برای دسترسی به این فیلدها از دو روش استفاده میکند و این روشها را موقع پیکربندی هایبرنت در فایل پیکربندی میتوانیم بهش اعلام کنیم . یکی از این روشها دسترسی مستقیم به فیلدهاست روش دیگر دسترسی به فیلدها از طریق همین متدهای getter__و setter میباشد .
دسترسی به وضعیت آبجکت از طریق فیلدها یا از طریق متدهای getter /setter ؟
همانطور که قبلاً گفتیم هایبریت به دو طریق میتواند به وضعیت یک آبجکت دسترسی داشته باشد دسترسی مستقیم به فیلدها و دسترسی به اون فیلدها از طریق متدهای getter / setter مرتبط با آنها . اینکه کدوم روش بهتر است جای بحث دارد . در اکثر مثالها و نمونه کدهایی که من به شخصه دیدم از روش اول یعنی دسترسی مستقیم به فیلدها استفاده میشود ولی دسترسی از طریق متدها دارای یک سری ملاحظات است که باید رعایت بشوند آن ملاحظات به این شرح هستند :
در هایبرنت یک مفهومی بنام dirty checking وجود دارد به این معنی که هایبرینت در هر لحظه وضعیت فعلی یک آبجکت ( attached object ) را رصد میکند و به محض مشاهده یک تغییر در وضعیت آن سعی میکند این تغییر را در data store ذخیره کند و با این sync کردن درستی و consistency اطلاعات را تضمین نماید . در هایبرنت آبجکتها بوسیله مقدار شان بررسی میشوند نه بوسیله ID آنها ( یعنی مکانی که در آنجا ذخیره شده است ) تا ببینید نیازی به عمل sync هست یا نه . در این حالت با اجرای کد زیر عمل syncی با دیتابیس رخ نخواهد داد .
public String getFirstname() {
return new String(firstname);
}
در چنین حالتی هایبرنت موقع get کردن تشخیص میدهد به روز اوری رخ داده بنابراین یک عمل sync با دیتا بیس را انجام میدهد در حالی که لازم نیس ولی چرا اینکار را میکند بخاطر اینکه در هنگام set کردن با arrany سروکار دارد ولی موقع get کردن با list درواقع آبجکت set با آبجکت get فرق دارد . اینها نکات ریزی هستند که در محیط های حساس (مثل نرم افزارهای بانکی و مالی ) اگر رعایت نشود ممکن است باعث ایجاد باگ هایی بشود که پیدا کردنشان شاید به این آسانی ها ممکن نباشد .
البته این مثالی که زدیم از نظر منطق هیچ مشکلی ندارد فقط با هر بار get کردن یک عمل syncو به روز اوری توی دیتابیس انجام خواهد داد که خب واقعاً لازم نیست .
تذکر : البته اگر ما روش دسترسی به فیلدها را برای هایبرنت روش مستقیم ا انتخاب کرده باشیم چنین متدهایی اصلاً تأثیری روی عملکرد هایبرنت نخواهد داشت و هایبرنت این متدها را نادیده خواهد گرفت .
پیادهسازی رابطه بین Object ها در هایبرنت :
در هایبرینت و ORM برای اینکه ارتباط بین دو آبجکت را نشان بدهیم از مفاهیم one- one ، one-many و many-many استفاده میکنند.گاهی ارتباط دو آبجکت یکطرفه و گاهی دوطرفه میشود .
برای نمایش ارتباط آبجکت X با آبجکت Y ، آبجکت Y را به عنوان یکی از property های آبجکت X اعلان میکنیم .
برای توصیف رابطه بین دو آبجکت از مثال کمک میگیریم به دیاگرام UML زیر توجه کنید :
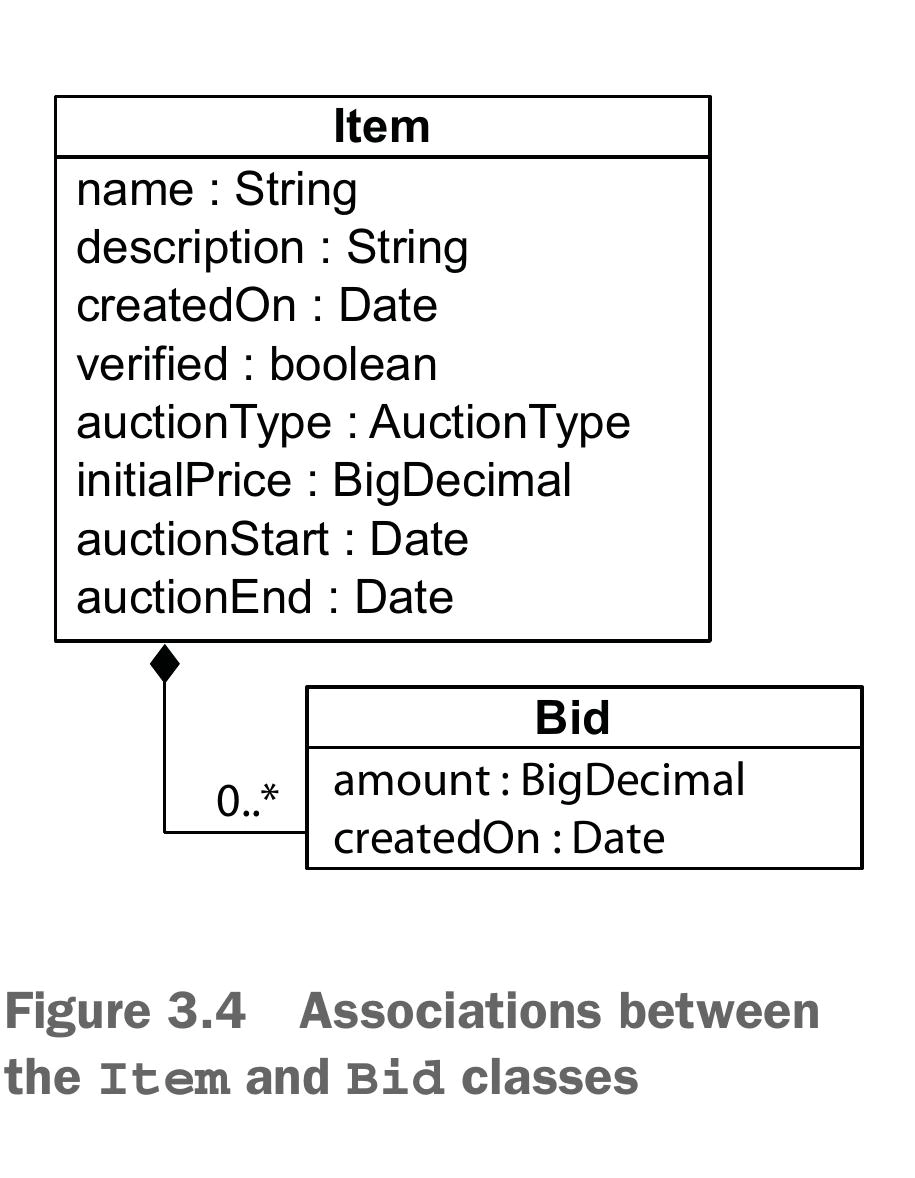
همچنین کد هریک از کلاسها را در زیر مشاهده میکنید :
public class Bid {
protected Item item;
public Item getItem() {
return item;
}
public void setItem(Item item) {
this.item = item;
}
}
public class Item {
protected Set<Bid> bids = new HashSet<Bid>();
public Set<Bid> getBids() {
return bids;
}
public void setBids(Set<Bid> bids) {
this.bids = bids;
}
}
رابطه بین این دو آبجکت از نوع one-many است و همچنین رابطه از نوع دوطرفه است .
در کد بالایی در کلاس Item چند نکته برنامه نویسی جالبی وجود دارد بد نیست به آنها اشاره کنیم :
protected Set<Bid> bids = new HashSet<Bid>();
در این خط کد علاوه بر اینکه اصل OO یعنی :
favor to interface over implementation
رعایت شده ( با تعریف کلکسیون از نوع واسط set ) ، ثانیاً در همان خط اعلان مقداردهی اولیه شده است این مقداردهی اولیه باعث میشود از خطای nullPointerException جلوگیری شود .
نکته سوم این است که ما نیاز داریم برای یک آیتم تعداد متمایزی Bid ثبت کنیم و از ثبت عناصر تکراری جلوگیری کنیم برای اینکار بجای لیست از set استفاده کردیم شاید به ذهن بیاید برای کارهای مرتب سازی در سمت UI استفاده از list بهتر باشد ولی باید بگوییم مرتب سازی جزو دغدغه های سطح ذخیره سازی نیست ثالثاً میتوانیم برای آبجکت bid فیلدی بنام زمان ثبت سفارش اضافه کنیم تا بر حسب تاریخ و زمان ثبت ، آنها را سمت UI مرتب کنیم .
نحوه مدیریت لینک بین دو آبجکت در کد جاوایی :
در جاوا برعکس Sql مدیریت لینک بین این دو آبجکت کمی مشکل و پیچیده است و بهتر است از یک best practice برای این مدل رابطهها پیروی کنیم . برای مدیریت لینک بین این دو از یکسری متد استفاده میشود به هنگام نوشتن منطق داخل این متدها یک اصل را باید رعایت کنیم و آن این است :
«فرض کن هیچ ORM و Hibernate نیست برای مدیریت لینک دو آبجکت»
مورد مهم دوم در مورد رابطه بین دو آبجکت این است از خودمان سؤال بپرسیم :
اول مرغ بود یا تخم مرغ . برعکس دنیای واقعی بایستی یک جواب شفاف برای این سؤال بدهیم . جواب باید یا مرغ باشد یا تخم مرغ . به زبان ساده یکی از دو ابجکت بایستی به عنوان آبجکت اصلی که قایم به ذات است فرض شود و دیگری به عنوان آبجکتی که وابسته به آبجکت اصلی است .
در مورد مثال بالایی البته مفهوم bid بدون وجود آیتم معنی ندارد . اول باید آیتمی به وجود بیاید تا برای آن bidی ثبت بشود . در چنین سناریو هایی باید موقع نوشتن متدهایی که لینک بین این دو را مدیریت میکند این موضوع را مد نظر قرار دهیم مثلاً وقتی دستور ثبت bid صادر میشود باید اول سراغ موجود آیتم برویم ببینم هست و اگر هس براساس آن و از طریق آن آبجکت عمل افزودن bid جدید به لیستش را انجام دهیم . با کد این موارد را نشان میدهیم .
anItem.getBids().add(aBid);
aBid.setItem(anItem);
کد زیر در کلاس item گنجانده میشود :
public void addBid(Bid bid) {
if (bid == null)
throw new NullPointerException("Can't add null Bid");
if (bid.getItem() != null)
throw new IllegalStateException("Bid is already assigned to an
➥ Item");
getBids().add(bid);
bid.setItem(this);
}
یعنی به هنگام مدیریت روابط دوطرفه دو موضوع را در کد مد نظر قرار میدهیم :
این فرایند کنترلی را مقایسه کنید با آن کاری که در سطح dbانجام میدهید در آنجا فقط کافیست این قید را اعلان کنید ( حتی به صورت ویزاردی اینکار میتواند صورت گیرد ) ولی همین قید را باید در سطح کد به صورت یک روال پیادهسازی کنید .
به هنگام تعریف getter و setter معمولاً برای فیلد Set bids هم این متدها ساخته میشه ولی در اینجا لازم است کمی با احتیاط رفتار کنیم . به این معنی که ما نباید اجازه بدهیم از بیرون کسی چنین کلکسیونی را ساخته و بی هیچ کنترلی آن را به این فیلد ست کند اصلاً متد کنترلی public void addBid(Bid bid) را برای این ساختیم تا عمل افزودن bid به کلکسیون به صورت کنترل شده صورت گیرد بنابراین نیاز به این متد یعنی setBids(set bids) نداریم میتوانیم آن را از سطح کلاس حذف کنیم همچنین برای متد getter . در مورد این متد نیاز داریم کمی محتاطانه رفتار کنیم بجای اینکه خود کلکسیون را برگردانیم میتوانیم کپی آن را به دنیای بیرون برگردانیم تا مطمین بشیم از بیرون کسی این کلکسیون را تغییر نخواهد داد . مثلاً با استفاده از این چنین کدی :
public class Bid {
protected Item item;
public Bid(Item item) {
this.item = item;
item.getBids().add(this);
}
public Item getItem() {
return item;
}
}
البته باید توجه کنیم که فیلد های ما نبایستی final تعریف بشوند همچنین در کلاس bid بایستی صراحتاً یک constructor بدون آرگومان برایش تعریف کنیم.
نحوه بکارگیری متادیتا ها برروی persitent object ها :
برای اینکه ابزارها و کتابخونه های ORM ی چون هایبرنت بتوانند آبجکتها را به جدول ها نگاشت کنندو حین این نگاشت ملاحظاتی را رعایت کنند نیاز است از یکسری متادیتا ها استفاده کنیم استفاده از متادیتا ها راهکار هوشمندی است تا دغدغه هایی که اصلاً مرتبط به domain object ها نیستند وارد حوزه کاری آنها نکنیم بلکه این متا دیتا ها شبه حاشیه نویسی در گوشه کنار کتابهاست و شما اصل متن را مطالعه میکنید هر جایی نیاز به توضیح و راهنمایی بیشتر باشد سراغ این حاشیه ها میروید . در هایبرنت دو روش حاشیه نوسی برای این افزودن این متادیتا ها در نظر گرفته :


 solmaz.oskouie
solmaz.oskouie